Hodnocení hollywoodských filmů v IBM SPSS Statistics

V tomto článku si představíme analýzu, která vznikla během individuálních analytických cvičení prezentovaných v semestrálním kurzu Statistická analýza dat v praxi. Máme k dispozici datový soubor charakterizující a hodnotící vybrané hollywoodské filmy za dobu čtyř let a stojíme před otázkou, co ovlivňuje divácké hodnocení těchto filmů? Má na hodnocení vliv studio, které film natočilo, nebo je významný žánr, případně rok, ve kterém byl film natočen?
Než začneme s analýzou dat, měli bychom vědět, co vlastně chceme dělat. Na co chceme získat odpověď? V semestrálním kurzu Statistická analýza dat v praxi se klade důraz na to, že analytik si musí položit při řešení úlohy tři otázky: Zda? Kolik? Proč?
1. Představení úlohy
Podívejme se třeba na divácké hodnocení hollywoodských filmů. Mě jako fanouška zajímá, co má vliv na to, jak publikum hodnotí daný film. Vytvořím si tedy model, který obsahuje tři nezávislé kategorizované proměnné, takzvané faktory, a jednu závislou číselnou proměnnou. Číselná proměnná je divácké hodnocení, faktory jsou rok, kdy byl film natočen, studio, které film natočilo a žánr filmu. Úloha je takto připravená pro analýzu rozptylu.
Moje tři otázky jsou následující:
- Existuje rozdíl v průměrném hodnocení filmů v závislosti na třech zmíněných faktorech?
- Jak vysoký vliv faktory mají, resp. je tento vliv statisticky významný?
- Pokud je některý z faktorů významný, proč tomu tak je, resp. k čemu mi vytvořený model bude?
2. Grafické zobrazení a první závěry
Udělejme si tři jednoduché analýzy rozptylu a podívejme se na grafy průměrů:

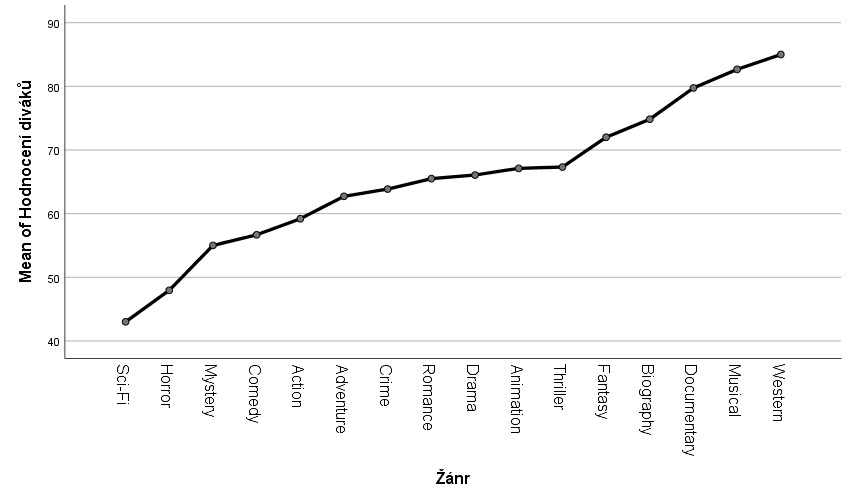
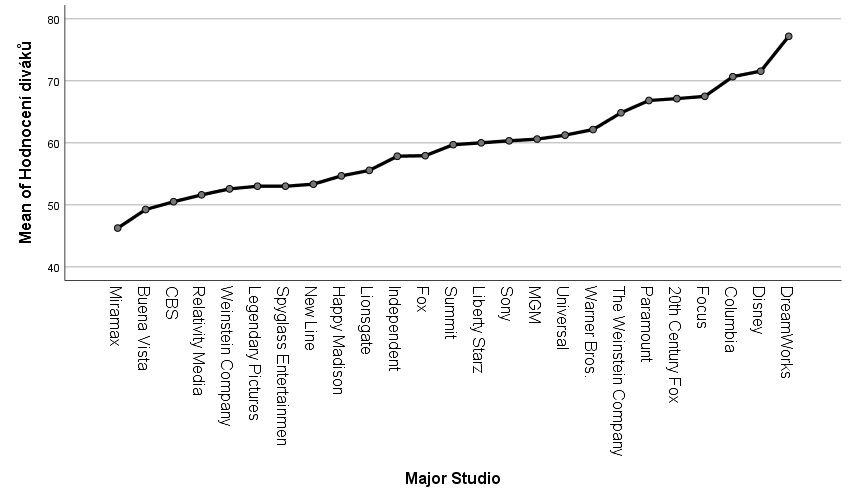
Už z těchto tří grafů můžeme usoudit odpověď na první otázku. Rozdíl v hodnocení hollywoodských filmů se zdá být ovlivněn každým ze tří faktorů. Jsou však tyto rozdíly statisticky významné? Když se podíváme na signifikance u provedených procedur, zjistíme, že všechny jsou velmi blízké nule. Všechny se tedy zdají statisticky významné. Ale jak jsou velké? Je hodnocení ovlivněno spíše rokem, kdy byl film uveden, nebo studiem, které film natočilo? K zodpovězení této otázky použijeme koeficient η2, který udává, kolik procent rozptylu je vysvětleno daným faktorem. Můžeme pak říct, že hodnocení je nejvíce ovlivněno žánrem, poté studiem a nakonec rokem. Ale co když mezi jednotlivými faktory dochází k interakci? Dokážeme vůbec model, který si vytvoříme, rozumně vysvětlit? Proč je důležitý rok, kdy byl film natočen?
3. Statistické modely
Další otázky vedou k dalším analýzám a nakonec získáme dva statisticky významné modely. Postup, jakým jsme se k nim dopracovali, je následující. Vytvoříme si model, kde jsou zpočátku všechny tři faktory i jejich interakce, a postupně faktory ubíráme podle toho, který z nich je nejméně významný. Nakonec získáme MODEL 1, kde jsou všechny členy statisticky významné, a právě ten nás zajímá. Obsahuje jen dva faktory jako hlavní, studio a žánr. Třetí faktor se nachází v modelu pouze v interakci rok*žánr (interakční člen znamená, že je významná kombinace obou členů zároveň). MODEL 2 jsme vytvořili proto, abychom zjistili, zda je interakce potřeba. Nebude lepší jednodušší model, kde je každý faktor významný jen sám o sobě, tedy ne v kombinaci s ostatními?
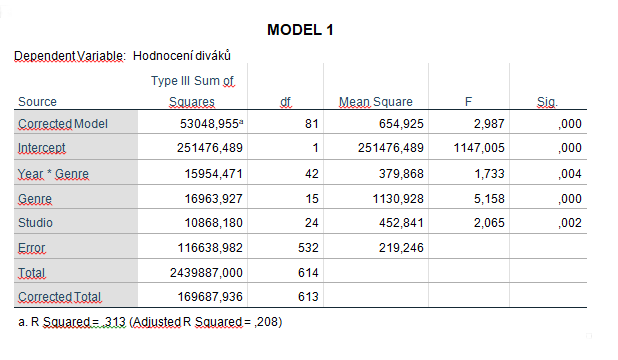
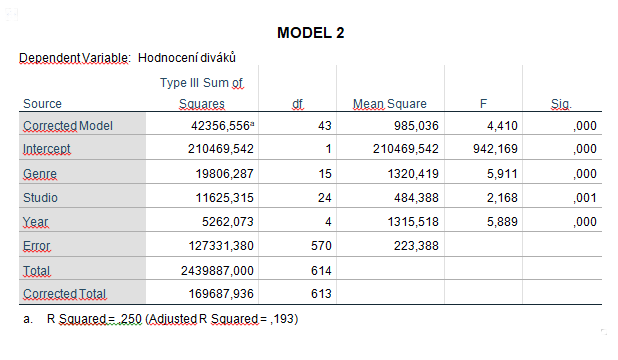
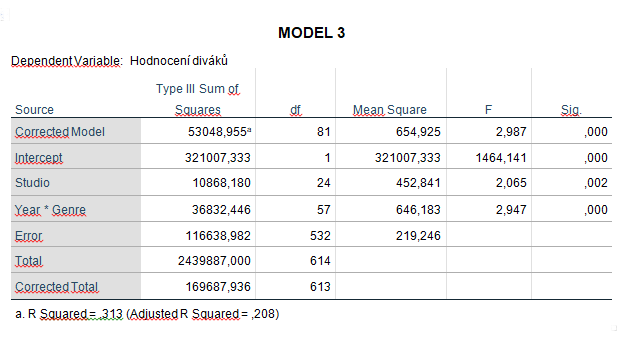
Nejlepší model je ten, který dokážeme rozumně vysvětlit. Navíc, modely by měly být užitečné. Mějme na paměti větu Georga Boxe: „All models are wrong, but some are useful.“ Když se zamyslím nad využitím svého modelu, jak ho budu jako fanoušek používat? Při výběru filmu si nejdříve vyberu studio, třeba DreamWorks. Pak si vyberu rok 2007 a v rámci tohoto roku vyberu žánr dle uvážení. Potřebuji mít v tomto procesu i samostatný faktor žánr, přestože vychází významně? Když otestuji model s hlavním faktorem studio a interakcí rok*žánr, zjistím, že vysvětlí stejné procento variability jako model, který má ještě navíc hlavní faktor žánr, tj. asi 31% (viz tabulky). Nový MODEL 3 je pro mě tedy nejužitečnější a zároveň vysvětluje největší procento variability ze všech tří.
4. Příklady předpovědí
Podívejme se ještě na konkrétní příklad predikovaného hodnocení pro film Hvězdný prach.

Náš uvažovaný model s hlavním faktorem studio a interakcí rok*žánr mu předpovídá hodnocení 85,56 a skutečně, film je diváky hodnocen 86 procenty. (V softwaru IBM SPSS Statistics je velmi jednoduché získat predikovanou hodnotu – stačí zaškrtnout volbu, že ji chceme nechat uložit jako novou proměnnou). Na druhou stranu třeba film Temný rytíř má předpovídané hodnocení jen 57,64 a ve skutečnosti ho diváci hodnotí 96 procenty.

Proč nám nevyšlo hodnocení Temného rytíře? V hodnocení samozřejmě hrají roli i jiné faktory, než ty, které jsou uvažované v modelu. Například obsazení nebo silný příběh jednoho z hlavních herců. Vždy je tedy potřeba myslet na to, že každý model je zjednodušením a nelze očekávat, že bezchybně odhadne všechny hodnoty.
Pro bližší seznámení s použitými procedurami doporučuji nápovědu programu IBM SPSS Statistics nebo navštivte některý z našich kurzů.
