Formy a úskalí sběru dat v praxi

Všem datovým úpravám, analýzám, predikcím a reportům musí předcházet fáze, ve které se data získávají. Pro někoho znamená získání dat export z již existujících zdrojů. Jak se data do těchto zdrojů dostala už nijak neřeší. Pro jiného znamená získání dat přímo jejich sběr. To znamená, že je musel někdo od někoho/něčeho získat a pomocí nějakého softwaru někam/nějak uložit. Sběr dat může, a většinou také bývá, organizačně, časově i finančně náročný. Rovněž způsoby nebo formy, jakými se data sbírají, se mohou výrazně lišit. V tomto článku se zaměříme na různé způsoby sběru dat od respondentů, jejich úskalí a používané praktiky.
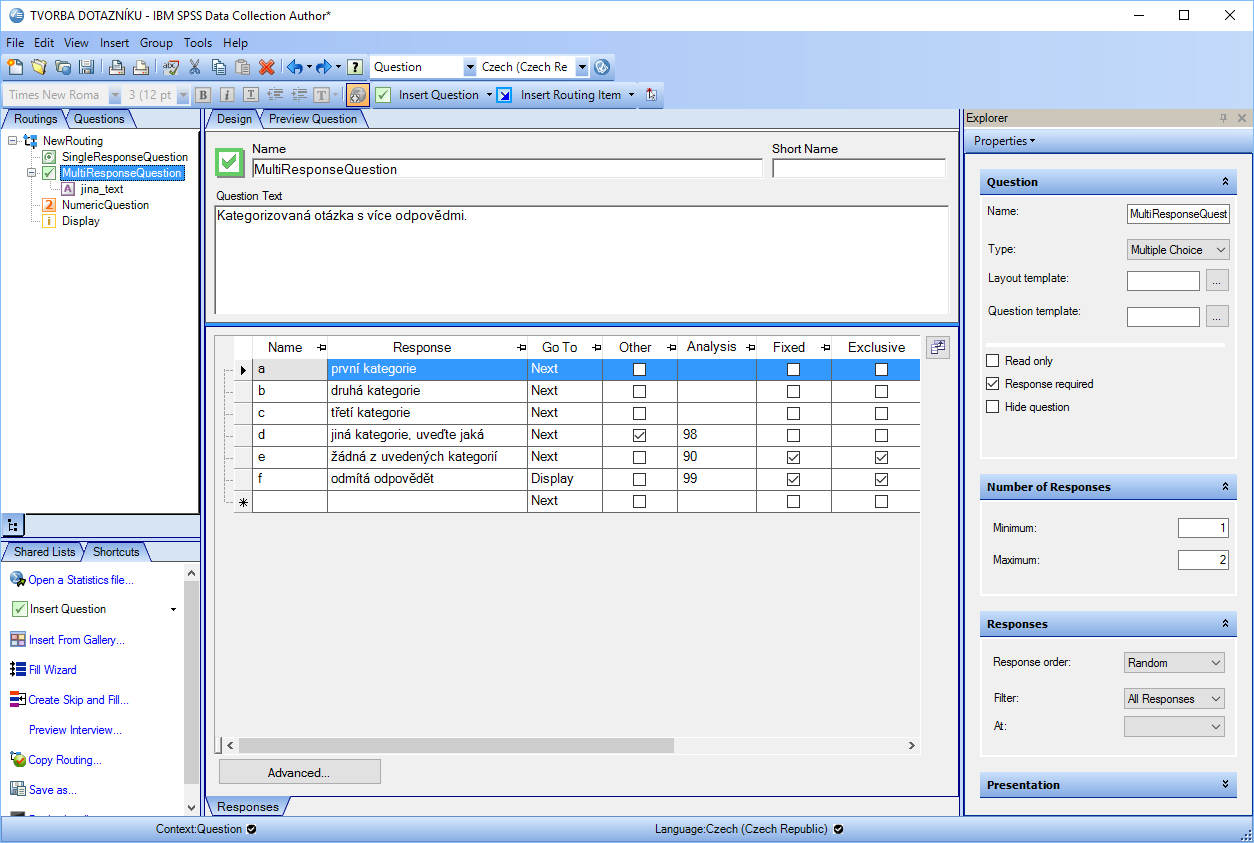
Sběr dat je nejčastěji realizován, pomineme-li tedy záznamy z čidel a jiných přístrojů, jako formulář či dotazník, eventuálně odpovědní arch. Může se jednat o výzkumná šetření nebo o jednoduché zadání požadovaných hodnot, například měsíční spotřeby energií jednotlivých závodů firmy. Ať už se bude řešit papírově či elektronicky, vždy je třeba odpovědět na různé typy otázek. Mohou jimi být jednoduché otázky textové, numerické či otázky na datum. Velmi používané jsou kategorizované otázky s jednou či více možnými odpověďmi. Podle možností softwaru lze vytvářet i komplexnější maticové otázky, typicky sestavené z výše uvedených typů.
Nástrojů pro různé formy sběru je celá řada, placených i volně dostupných. Některé jsou vhodnější pro webové, jiné pro telefonické dotazování. Většina dostačuje pro jednoduché, přímočaré dotazování. Velice často však zákazník potřebuje sofistikovaný software pro komplexní dotazníky, se složitým logickým průchodem s možností pokročilých výzkumných operací jako je náhodné pořadí kategorií, bloků otázek, podmíněné kladení otázek apod. Ideální je pak takový nástroj, který by unifikovaným způsobem byl schopen vytvářet dotazníky pro libovolnou formu sběru dat a následně pak používal jednotnou datovou platformu pro jejich uložení.
Klasický rozhovor tváří v tvář
Ačkoli existuje silný trend realizovat sběr dat přes internet či telefonicky, pořád existují situace, kdy tyto přístupy nejsou vhodné. Typicky se jedná o rozsáhlé, časově náročné dotazníky, jejichž rozsah a struktura by pro respondenta byly příliš složité. Nebo podnikové/společenské postavení respondenta nenabízí vhodnější formu. Dost těžko budeme telefonovat vysokým manažerům a ředitelům, nebo po nich budeme chtít vyplnit dotazník online. Rovněž složitě strukturované, jedno i více hodinové, rozhovory nejsou telefonicky či online vyplnitelné. Pro klasický rozhovor nám sice stačí tužka a papír, ale vyplatí se používat software, který by pomáhal tazateli v průchodu dotazníkem a řídil by logiku a věcnou správnost odpovědí. Pokud se provádí sběr dat papírově, hodil by se nám software, který by odpovědi dokázal převést do elektronické strukturované podoby.
Papírový záznam dotazníku (PAPI)
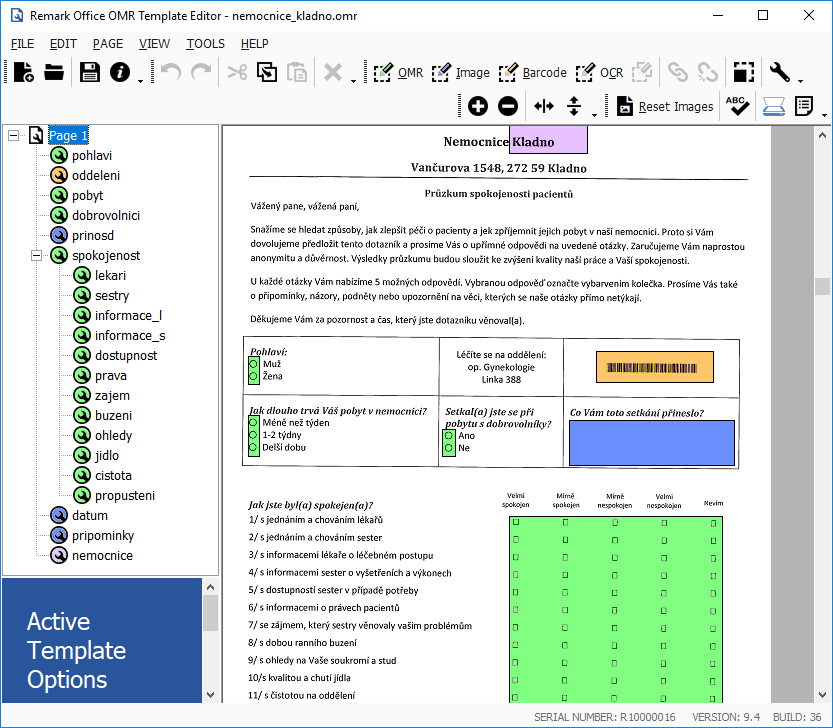
Ať už se jedná o záznam, který provádí tazatel při rozhovoru s respondentem, nebo přímo respondent osobně, vždy se provádí papírově. Při rozhovoru zaznamenávaném tazatelem se často používá, pro ušetření místa, odpovědní arch. Na něm pak nejsou texty otázek a instrukcí, ale pouze prostor na odpovědi. Původnímu desetistránkovému dotazníku pak odpovídá třeba jenom jednostránkový A4 odpovědní arch. To je samozřejmě jednodušší pro další zpracování a digitalizaci. Méně papírů = rychlejší skenování a zpracování = menší pravděpodobnost, že se někde něco pokazí, zasekne, špatně naskenuje atd. Při skenování pak máme na výběr z programů používající dvě technologie. První, technologie OMR, rozeznává značky vyplněno/nevyplněno a různé čárové a jiné kódy. Druhá technologie OCR rozeznává i rukou psané texty a čísla. OCR softwary jsou však výrazně dražší a nikdy nebudou při rozpoznávání znaků dosahovat 100% spolehlivosti.
Elektronický záznam dotazníku (CAPI)
Představuje pokročilejší formu sběru dat. Tazatel má pro zaznamenání odpovědí k dispozici software. Tím odpadá nutnost převodu papírového dotazníku do elektronické podoby. Další výhodou je možnost zajištění logicky správného průchodu dotazníkem, podmíněně řízeným odpověďmi respondenta. Tazatel se tak může soustředit na samotný rozhovor místo, aby v instrukcích hledal další postupy. Tazatelský software je typicky nainstalován na notebooku/tabletu a data se ukládají lokálně. Problém může nastat tehdy, není-li řešena synchronizace jednotlivých zařízení, které jsou často i dlouhodobě rozmístěny v terénu. Synchronizací se myslí aktualizace stávajících, případně distribuce nových dotazníků a stažení dat do jednoho centrálního datového zdroje.
Telefonické dotazování (CATI)
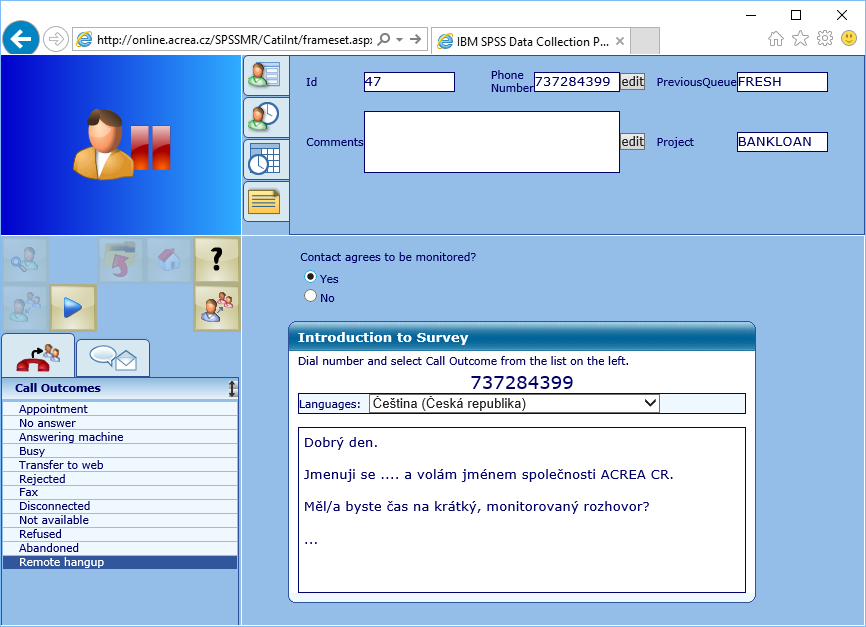
Stále používané je i telefonické dotazování. Většina z nás se ho již někdy zúčastnila. Většinou se jedná o krátký (ve skutečnosti vždy delší než původně avizováno), monitorovaný rozhovor. Z hlediska výzkumného je třeba si uvědomit, že ne všechny výzkumy je vhodné/možné realizovat telefonicky. Pro realizaci telefonického sběru dat je zapotřebí software, ideálně dostupný online, který by tazateli call centra automaticky nabízel a spravoval kontakty a zároveň připravil rozhraní pro zaznamenání odpovědí. Ohledně správy kontaktů by například v případě neuskutečněného hovoru takovou informaci zaevidoval a podle ní se k danému kontaktu v budoucnu zachoval. Neexistující či faxové číslo nemá smysl vytáčet znovu, ale je-li obsazeno nebo hovor nikdo nepřijímá, klidně můžeme hovor za 10/20 minut opakovat. Pokud už hovor probíhá, musí ho jít přerušit a kdykoli znovu navázat v místě přerušení. Pro klíčové aspekty výzkumů, jako jsou například kvóty, je nutno mít centrální evidenci telefonních kontaktů a plnění kvótních cílů. Aby toho bylo dosaženo, je potřeba data ukládat do jednoho centrálního datového úložiště. Architektura řešení musí být decentralizovaná ve smyslu umístění telefonických operátorů, ale centralizovaná ve smyslu správy projektů, kvót a sbíraných dat.
Internetový sběr dat (CAWI)
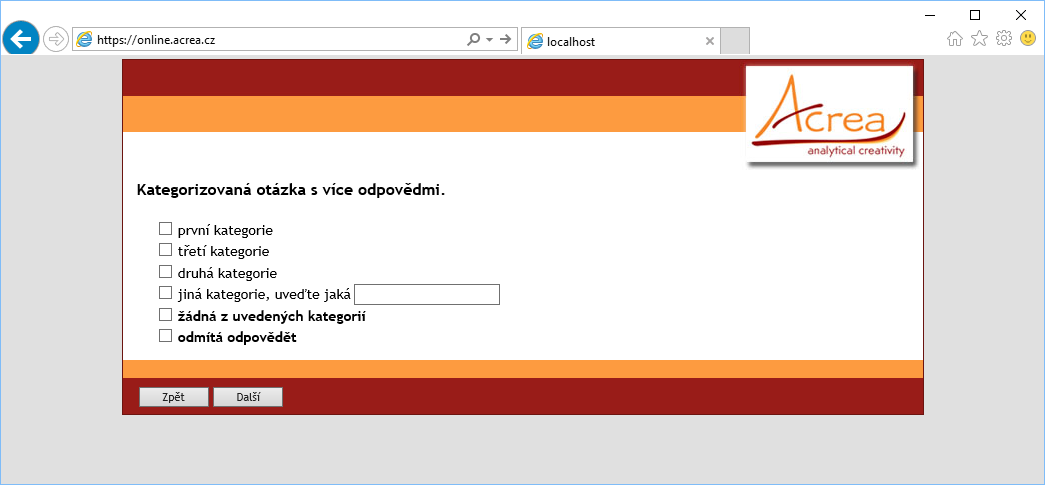
Asi nejpoužívanější způsob sběru, o kterém systémově platí, že by měl umožňovat to, co telefonický sběr. Musí tedy existovat jedno centrální datové úložiště, jedna centrální administrace kontaktů v případě, že sběr není anonymní, ale je adresný. Díky tomu je možno dotazník kdykoli přerušit a později i opakovaně navázat v místě přerušení. Kvóty by měly fungovat obdobně. Je-li kvóta naplněna, přerušit dotazník, nebo respondenta přesměrovat na jiný dotazník. Ideálně tak, aby respondent nic nepoznal. Důležité je, aby když už byl kontakt navázán a respondent je ochotný dotazník vyplnit, abychom o něj nepřišli tím, že se ho v první rozřazovací/vyřazovací otázce na něco zeptáme a následně mu poděkujeme s tím, že se nám nehodí do našeho výzkumu. Webové dotazování musí opět, stejně jako všechny předchozí, umět řídit logický průchod dotazníkem. To znamená podmíněné zobrazování otázek podle respondentových odpovědí, přeskoky, filtry, rozřazovací/vyřazovací otázky, náhodné pořadí odpovědí či bloku otázek apod. Kromě toho velice často je nutné, abychom do dotazníku připojili aktuální informace z externího zdroje, například CRM. A to nejen tak, že se například respondentovi zobrazí aktuální seznam používaných služeb či zůstatek na účtu, ale tato informace se použije i pro další dotazování jako filtr v další otázce či logické podmínce.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.
